
Avec l’évolution des temps, un travail efficace devient de plus en plus important dans notre vie quotidienne. Comme dans les domaines de la finance, de l'éducation, des assurances, de la bureautique électronique du gouvernement et des entreprises, les produits OCR/scanner de documents y accordent un rôle très important. Les produits OCR permettent de réduire considérablement la charge de travail du personnel et d'améliorer l'efficacité du travail.



Qu'est-ce que la reconnaissance optique de caractères (OCR) ?
La technologie de reconnaissance optique de caractères (OCR) est un processus commercial efficace qui permet d'économiser du temps, des coûts et d'autres ressources en utilisant des capacités automatisées d'extraction et de stockage de données.
La reconnaissance optique de caractères (OCR) est parfois appelée reconnaissance de texte. Un programme OCR extrait et réutilise les données des documents numérisés, des images de caméra et des fichiers PDF contenant uniquement des images. Le logiciel OCR distingue les lettres sur l'image, les met en mots puis met les mots en phrases, permettant ainsi l'accès et la modification du contenu original. Cela élimine également le besoin de saisie manuelle des données.
Les systèmes OCR utilisent une combinaison de matériel et de logiciels pour convertir des documents physiques imprimés en texte lisible par machine. Le matériel - tel qu'un scanner optique ou un circuit imprimé spécialisé - copie ou lit le texte ; ensuite, le logiciel gère généralement le traitement avancé.
Les logiciels OCR peuvent tirer parti de l'intelligence artificielle (IA) pour mettre en œuvre des méthodes plus avancées de reconnaissance intelligente des caractères (ICR), comme l'identification des langues ou des styles d'écriture manuscrite. Le processus d'OCR est le plus souvent utilisé pour transformer des documents juridiques ou historiques sur papier en documents PDF afin que les utilisateurs puissent modifier, formater et rechercher les documents comme s'ils étaient créés avec un traitement de texte.
Comment fonctionne la reconnaissance optique de caractères ?
La reconnaissance optique de caractères (OCR) utilise un scanner pour traiter la forme physique d'un document. Une fois toutes les pages copiées, le logiciel OCR convertit le document en une version bicolore ou noir et blanc. L'image ou le bitmap numérisé est analysé pour détecter les zones claires et sombres, et les zones sombres sont identifiées comme des caractères qui doivent être reconnus, tandis que les zones claires sont identifiées comme arrière-plan. Les zones sombres sont ensuite traitées pour trouver des lettres alphabétiques ou des chiffres numériques. Cette étape consiste généralement à cibler un caractère, un mot ou un bloc de texte à la fois. Les caractères sont ensuite identifiés à l'aide de l'un des deux algorithmes suivants : la reconnaissance de formes ou la reconnaissance de caractéristiques.
La reconnaissance de formes est utilisée lorsque le programme OCR reçoit des exemples de texte dans différentes polices et formats pour comparer et reconnaître les caractères du document numérisé ou du fichier image.
La détection des fonctionnalités se produit lorsque l'OCR applique des règles concernant les caractéristiques d'une lettre ou d'un chiffre spécifique pour reconnaître les caractères du document numérisé. Les fonctionnalités incluent le nombre de lignes inclinées, de lignes croisées ou de courbes dans un caractère. Par exemple, la lettre majuscule « A » est stockée sous forme de deux lignes diagonales qui se rejoignent par une ligne horizontale au milieu. Lorsqu'un caractère est identifié, il est converti en un code ASCII (American Standard Code for Information Interchange) que les systèmes informatiques utilisent pour gérer d'autres manipulations.
Un programme OCR analyse également la structure d'une image de document. Il divise la page en éléments tels que des blocs de textes, des tableaux ou des images. Les lignes sont divisées en mots puis en caractères. Une fois les caractères identifiés, le programme les compare à un ensemble d'images de motifs. Après avoir traité toutes les correspondances probables, le programme vous présente le texte reconnu.
L'OCR est souvent utilisée comme une technologie cachée, alimentant de nombreux systèmes et services bien connus dans notre vie quotidienne. Les cas d'utilisation importants, mais moins connus, de la technologie OCR incluent l'automatisation de la saisie de données, l'assistance aux personnes aveugles et malvoyantes et l'indexation de documents pour les moteurs de recherche, tels que les passeports, les plaques d'immatriculation, les factures, les relevés bancaires, les cartes de visite et la reconnaissance automatique des plaques d'immatriculation. .
Caractéristiques par rapport aux scanners traditionnels :
1. Léger, facile à transporter et à installer ;
2. Le temps de numérisation est court, le temps de numérisation normal est de 1 à 2 secondes et vous pouvez l'obtenir immédiatement ;
3. Faible coût
4. Il peut effectuer une reconnaissance OCR sur les images capturées, convertir les images en documents modifiables WORD et les composer automatiquement ;
5. Grâce à l'intégration de la technologie de télécopie sans papier, même s'il n'y a pas de télécopieur, vous pouvez toujours envoyer des télécopies, ce qui améliore considérablement l'efficacité de la télécopie ;
Cas d'utilisation de la reconnaissance optique de caractères
Le cas d’utilisation le plus connu de la reconnaissance optique de caractères (OCR) consiste à convertir des documents papier imprimés en documents texte lisibles par machine. Une fois qu'un document papier numérisé passe par le traitement OCR, le texte du document peut être modifié avec un traitement de texte comme Microsoft Word ou Google Docs.
L'OCR permet d'optimiser la modélisation du Big Data en convertissant des documents papier et des images numérisées en fichiers PDF lisibles par machine et consultables. Le traitement et la récupération d'informations précieuses ne peuvent pas être automatisés sans d'abord appliquer l'OCR dans les documents où les couches de texte ne sont pas déjà présentes.
Grâce à la reconnaissance de texte OCR, les documents numérisés peuvent être intégrés dans un système Big Data qui est désormais capable de lire les données client à partir des relevés bancaires, des contrats et d'autres documents imprimés importants. Au lieu de demander aux employés d'examiner d'innombrables documents image et d'introduire manuellement les entrées dans un flux de travail automatisé de traitement du Big Data, les organisations peuvent utiliser l'OCR pour automatiser l'étape d'entrée de l'exploration de données. Le logiciel OCR peut identifier le texte de l'image, extraire le texte des images, enregistrer le fichier texte et prendre en charge les formats jpg, jpeg, png, bmp, tiff, pdf et autres.
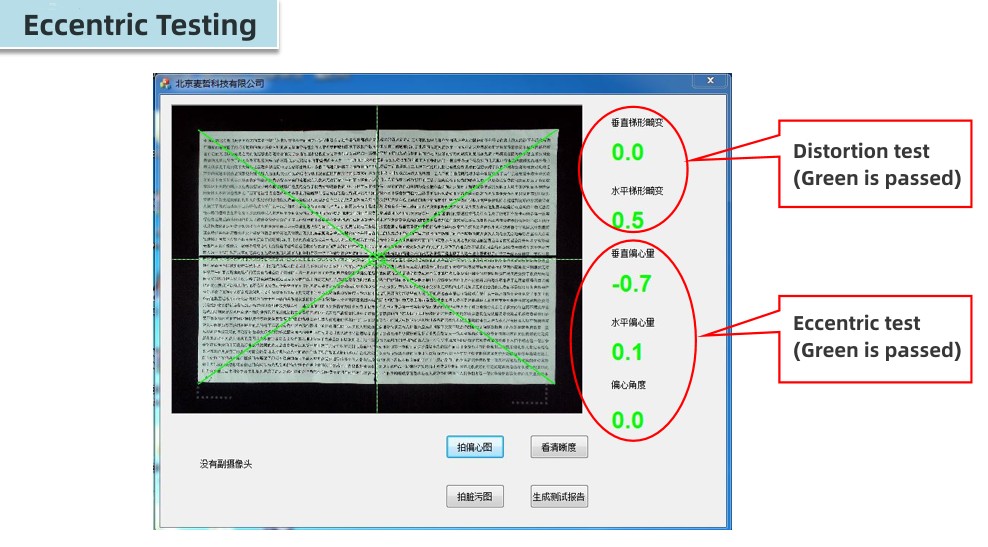
Sur cette base, Hampo allancemented une série de modules de caméra dequi de5MP-16MP de définition. Au début de la phase de développement de Hampo, notre équipe a produit un premier module de caméra USB de type 5MP pour scanner de documents à grande vitesse ;Avec ledemande demarché, Des modules de caméra USB 8MP, 13MP et même 16MP ont étéproduit. Quoi'De plus, la demande d'une caméra, de deux caméras et de plusieurs caméras est appliquée au scanner de documents.



Plus personnalisé requis, veuillez nous contacter, nous pourrions concevoir un produit satisfaisantmodule camérapour votre scanner de documents OCR/OCV.
Heure de publication : 23 février 2023



