
Con lo sviluppo dei tempi, il lavoro efficiente sta diventando sempre più importante nella nostra vita quotidiana. Ad esempio nei settori della finanza, dell'istruzione, delle assicurazioni, dell'ufficio elettronico governativo e aziendale, i prodotti OCR/scanner per documenti ricoprono un ruolo molto importante in questo. Con i prodotti OCR si verificano, che riducono notevolmente il carico di lavoro del personale, migliorano l'efficienza del lavoro.



Che cos'è il riconoscimento ottico dei caratteri (OCR)?
La tecnologia di riconoscimento ottico dei caratteri (OCR) è un processo aziendale efficiente che consente di risparmiare tempo, costi e altre risorse utilizzando funzionalità automatizzate di estrazione e archiviazione dei dati.
Il riconoscimento ottico dei caratteri (OCR) viene talvolta definito riconoscimento del testo. Un programma OCR estrae e riutilizza i dati da documenti scansionati, immagini della fotocamera e PDF di sole immagini. Il software OCR individua le lettere sull'immagine, le trasforma in parole e quindi inserisce le parole in frasi, consentendo così l'accesso e la modifica del contenuto originale. Elimina inoltre la necessità di inserire manualmente i dati.
I sistemi OCR utilizzano una combinazione di hardware e software per convertire documenti fisici stampati in testo leggibile dalla macchina. L'hardware, come uno scanner ottico o un circuito stampato specializzato, copia o legge il testo; quindi, il software in genere gestisce l'elaborazione avanzata.
Il software OCR può sfruttare l'intelligenza artificiale (AI) per implementare metodi più avanzati di riconoscimento intelligente dei caratteri (ICR), come l'identificazione delle lingue o degli stili di scrittura. Il processo OCR è più comunemente utilizzato per trasformare documenti legali o storici cartacei in documenti PDF in modo che gli utenti possano modificare, formattare e cercare i documenti come se fossero stati creati con un elaboratore di testi.
Come funziona il riconoscimento ottico dei caratteri?
Il riconoscimento ottico dei caratteri (OCR) utilizza uno scanner per elaborare la forma fisica di un documento. Una volta copiate tutte le pagine, il software OCR converte il documento in una versione a due colori o in bianco e nero. L'immagine o la bitmap acquisita viene analizzata per individuare le aree chiare e scure e le aree scure vengono identificate come caratteri che devono essere riconosciuti, mentre le aree chiare vengono identificate come sfondo. Le aree scure vengono quindi elaborate per trovare lettere alfabetiche o cifre numeriche. Questa fase in genere prevede il targeting di un carattere, una parola o un blocco di testo alla volta. I caratteri vengono quindi identificati utilizzando uno dei due algoritmi: riconoscimento di modelli o riconoscimento di caratteristiche.
Il riconoscimento dei modelli viene utilizzato quando al programma OCR vengono forniti esempi di testo in vari caratteri e formati per confrontare e riconoscere i caratteri nel documento scansionato o nel file immagine.
Il rilevamento delle caratteristiche avviene quando l'OCR applica regole riguardanti le caratteristiche di una lettera o di un numero specifico per riconoscere i caratteri nel documento scansionato. Le caratteristiche includono il numero di linee angolate, incrociate o curve in un carattere. Ad esempio, la lettera maiuscola "A" viene memorizzata come due linee diagonali che si incontrano con una linea orizzontale al centro. Quando un carattere viene identificato, viene convertito in un codice ASCII (American Standard Code for Information Interchange) che i sistemi informatici utilizzano per gestire ulteriori manipolazioni.
Un programma OCR analizza anche la struttura dell'immagine di un documento. Divide la pagina in elementi come blocchi di testi, tabelle o immagini. Le righe sono divise in parole e poi in caratteri. Una volta individuati i caratteri, il programma li confronta con una serie di immagini di pattern. Dopo aver elaborato tutte le probabili corrispondenze, il programma ti presenta il testo riconosciuto.
L'OCR viene spesso utilizzato come tecnologia nascosta, che alimenta molti sistemi e servizi ben noti nella nostra vita quotidiana. Casi d'uso importanti, ma meno conosciuti, della tecnologia OCR includono l'automazione dell'immissione dei dati, l'assistenza alle persone non vedenti e ipovedenti e l'indicizzazione di documenti per i motori di ricerca, come passaporti, targhe, fatture, estratti conto, biglietti da visita e riconoscimento automatico delle targhe. .
Caratteristiche rispetto agli scanner tradizionali:
1. Leggero, facile da trasportare e da installare;
2. Il tempo di scansione è breve, il tempo di scansione normale è 1-2S e puoi ottenerlo immediatamente;
3. Basso costo
4. Può eseguire il riconoscimento OCR sulle immagini catturate, convertire le immagini in documenti modificabili WORD e comporle automaticamente;
5. Incorporando la tecnologia fax senza carta, anche se non è presente un fax, è comunque possibile inviare fax, il che migliora significativamente l'efficienza del fax;
Casi d'uso del riconoscimento ottico dei caratteri
Il caso d'uso più noto per il riconoscimento ottico dei caratteri (OCR) è la conversione di documenti cartacei stampati in documenti di testo leggibili dalla macchina. Una volta che un documento cartaceo scansionato passa attraverso l'elaborazione OCR, il testo del documento può essere modificato con un elaboratore di testi come Microsoft Word o Google Docs.
L'OCR consente l'ottimizzazione della modellazione di big data convertendo documenti cartacei e immagini scansionate in file PDF leggibili dalle macchine e ricercabili. L'elaborazione e il recupero di informazioni preziose non possono essere automatizzati senza prima applicare l'OCR nei documenti in cui non sono già presenti livelli di testo.
Con il riconoscimento del testo OCR, i documenti scansionati possono essere integrati in un sistema big data che ora è in grado di leggere i dati dei clienti da estratti conto, contratti e altri importanti documenti stampati. Invece di chiedere ai dipendenti di esaminare innumerevoli documenti di immagini e inserire manualmente gli input in un flusso di lavoro automatizzato di elaborazione di big data, le organizzazioni possono utilizzare l'OCR per automatizzare la fase di input del data mining. Il software OCR può identificare il testo nell'immagine, estrarre il testo nelle immagini, salvare il file di testo e supportare jpg, jpeg, png, bmp, tiff, pdf e altri formati.
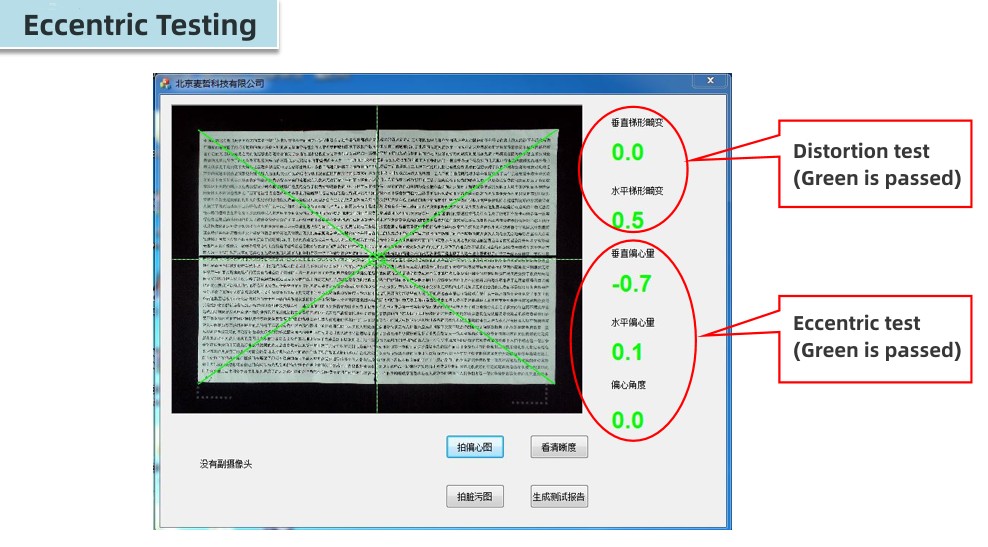
Sulla base di questo, Hampo halaunched una serie di moduli fotocamera dada quale5MP-16MP di definizione. All'inizio della fase di sviluppo di Hampo, il nostro team ha prodotto un modulo fotocamera USB da 5 MP di primo tipo per scanner di documenti ad alta velocità;Con ilrichiesta dimercato, Sono stati disponibili moduli fotocamera USB da 8 MP, 13 MP e persino 16 MPprodotto. Che cosa'C'è di più, la richiesta di una fotocamera, fino a 2 fotocamere e più fotocamere applicate allo scanner di documenti.



Richiesto più personalizzato, ti preghiamo di contattarci, potremmo progettare un soddisfattomodulo fotocameraper il tuo scanner di documenti OCR/OCV.
Orario di pubblicazione: 23 febbraio 2023



